When it comes to performance optimization I have a single piece of advice for you: Reduce the amount of queries, period. Forget about parallelizing, List vs. Array, a StringBuilder or loop unrolling, if you have a loop with a Retrieve inside, it’s almost always magnitudes more efficient to look at queries than anything else. Just because of the latency. If you have a loop of 10.000 items with a retrieve inside which takes 50ms, that’s 500 seconds. There are of course other methods to discuss like ExecuteMultiple and BypassCustomPluginExecution, but queries are the easiest and most efficient optimization to try.
Select Many Relationships
Using the Navigation Properties of Earlybounds you can load a related entity. The following query starts at the account and loads all related contacts.
var contacts = ctx.AccountSet
.Where(_ => _.Id == accountId)
.SelectMany(_ => _.contact_customer_accounts)
.Select(_ => new Contact { FirstName = _.FirstName, LastName = _.LastName })
.ToList();
That alone does not yield an immediate optimization, because I could have expressed that as well with a “simple” query.
var contacts2 = ctx.ContactSet
.Where(_ => _.ParentCustomerId.Id == accountId)
.Select(_ => new Contact { FirstName = _.FirstName, LastName = _.LastName })
.ToList();
Select Relationship
var contact = ctx.AccountSet
.Where(_ => _.Id == accountId)
.Select(_ => _.account_primary_contact)
.Select(_ => new Contact { FirstName = _.FirstName, LastName = _.LastName })
.FirstOrDefault();
This sample is a little different and this time it’s an actual saving. We are selecting a single value relationship here, the primary contact of an account. If we do the same with simple queries, we will need two queries. Doing it with a single query saves the latency once, but will put a little more load on the database to perform the join, which is usually far less than a latency.
var account = ctx.AccountSet
.Where(_ => _.Id == accountId)
.Select(_ => new Account { PrimaryContactId = _.PrimaryContactId })
.First();
var contact2 = ctx.ContactSet
.Where(_ => _.Id == account.PrimaryContactId.Id)
.Select(_ => new Contact { FirstName = _.FirstName, LastName = _.LastName })
.FirstOrDefault();
Sadly this method still has some shortcomings, what if I want both values from the contact and account? The following code DOES NOT WORK, it will only fill the FirstName property.
var contacts = ctx.ContactSet
.Where(_ => _.Id == contactId)
.Select(_ => new Contact { FirstName = _.FirstName, contact_customer_accounts = _.contact_customer_accounts })
.ToList();
Joining
If we need both entities, we will have to switch to query syntax. I like to use the method syntax a lot because in my opinion, it’s quite readable for simple queries, but for these larger ones, arguably, query syntax is the better choice.
var model = (from contact in ctx.ContactSet
join account in ctx.AccountSet on contact.ParentCustomerId.Id equals account.AccountId
where contact.ContactId == contactId
select new
{
Contact = new Contact { FirstName = contact.FirstName },
Account = new Account { Name = account.Name }
}).FirstOrDefault();
That sample outputs both the Account and Contact here. There are some things to observe here. First, I’ve used a dynamic here for the select (new {...}). This only works within the calling method, if you need to return both values to another method, consider making a small class or struct. Or you could return a Tuple<Contact,Account>, but access with tuple.Item1 and tuple.Item2 is arguably not very readable.
Also, notice how I’ve used contact.ContactId in the where clause and account.AccountId in the join. Using contact.Id is legal in the simple query below, but if you are working with a Join, you will have to use the long id names instead.
var cont = (from contact in ctx.ContactSet
where contact.Id == contactId
select new Contact { FirstName = contact.FirstName }
).FirstOrDefault();
Filtering on related
Another cool feature here is the ability to filter on the related entity. So in the sample below, we are only caring about the Contact, but we don’t have the ID of the Account yet. A simple query could mean that we first get the Account with that exact Name and then query by ParentCustomerId, but with a join, we can filter directly by account.Name.
var cont = (from contact in ctx.ContactSet
join account in ctx.AccountSet on contact.ParentCustomerId.Id equals account.AccountId
where account.Name == "Alpine Ski House (sample)"
select new Contact { FirstName = contact.FirstName }
).ToList();
Putting it all together
The last query is everything in one: We will do two joins by also looking at the PrimaryContactId of the Account. We will also query by a field on the account and we will return all 3 records, the contact, its account and the primary contact of the account.
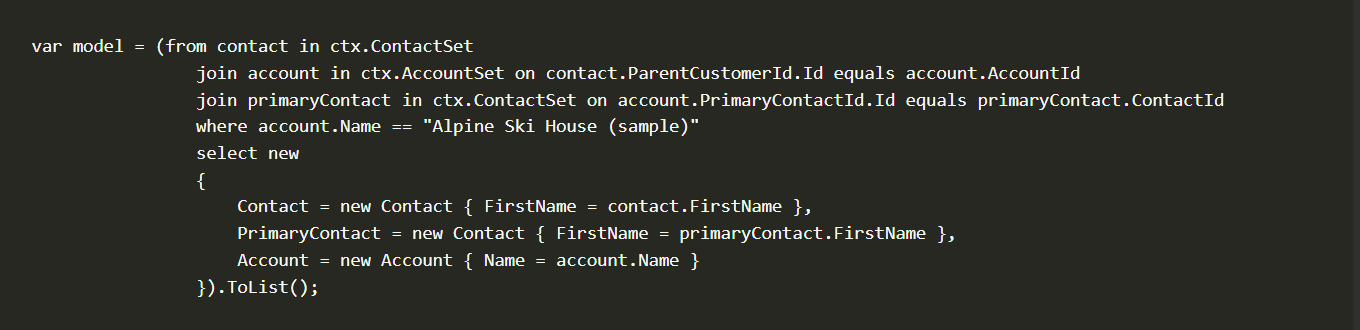
var model = (from contact in ctx.ContactSet
join account in ctx.AccountSet on contact.ParentCustomerId.Id equals account.AccountId
join primaryContact in ctx.ContactSet on account.PrimaryContactId.Id equals primaryContact.ContactId
where account.Name == "Alpine Ski House (sample)"
select new
{
Contact = new Contact { FirstName = contact.FirstName },
PrimaryContact = new Contact { FirstName = primaryContact.FirstName },
Account = new Account { Name = account.Name }
}).ToList();
Now it gets a little special: Let’s assume we have 2 contacts that have that account as ParentCustomer. That means that the query will return 2 results. And that also means 2 Contacts, 2 Accounts and 2 PrimaryContacts. So you might need to post-process that result before handing it back to logic, e.g. by grouping by Account.Id. Or the logic simply does not care. Need a sample? A tool exporting a .csv file with a row for each contact with some values from Account and PrimaryContact simply would iterate through the results and write down the values.
Summary
Relationships and Joining are a great way to reduce queries and thus latency. Before thinking about any other optimization for slow Tools, APIs or Plugins, check your queries first and think about their dynamics. If query1 returns 100k results and for each result, another query2 has to be fired that is a BIG deal. We will soon look into optimizations for writing data to Dataverse as well to optimize you further!